Final Write Up
Summary
We implemented Monte Carlo Tree Search algorithm for Go, and parallelized it using OpenMP on CPU, and Cuda on GPU. Then we compared the performance of these three implementations. Our deliverables include figures describing the performance improvemnt in terms of number of simulated games, and win ratios between different implementations.
Background
In this project we'll try to parallelize Monte Carlo Tree Search algoritm. The basic data structure we use here is tree. The tree will grow from one single node, with the following 4 oeprations: Selection, Expansion, Simulation and Backpropagation.
Selection: If a node has been visited and searched before, we use some evaluation function to determine which child node we should use to walk down the tree. This is a multi-arm bandit problem and here we use Upper Confidence bound applied to Trees (UCT) as the evaluation function, to balance exploration and exploition.
Expansion: If a node has not been searched before, we will try to expand the node by finding all possible next moves, as the children of the node, which are also the leaf nodes of the tree.
Simulation: For the leaf nodes that are just expanded, we'll play lots of games on the node using random choices, and record the number of simulations and wins. The more simulations we do on a single node, the better performance we'll get. Because all simulations are played independently, this is the main part we're going to parallelize.
Backpropagation: For all the simulations we run on the leaf nodes, the number of wins and simulations will be propagated back to its ancestors to update their records. Then we can find the best next move from the root node through its children's win/loss ratio. The picture folloing may help explain the 4 phases:
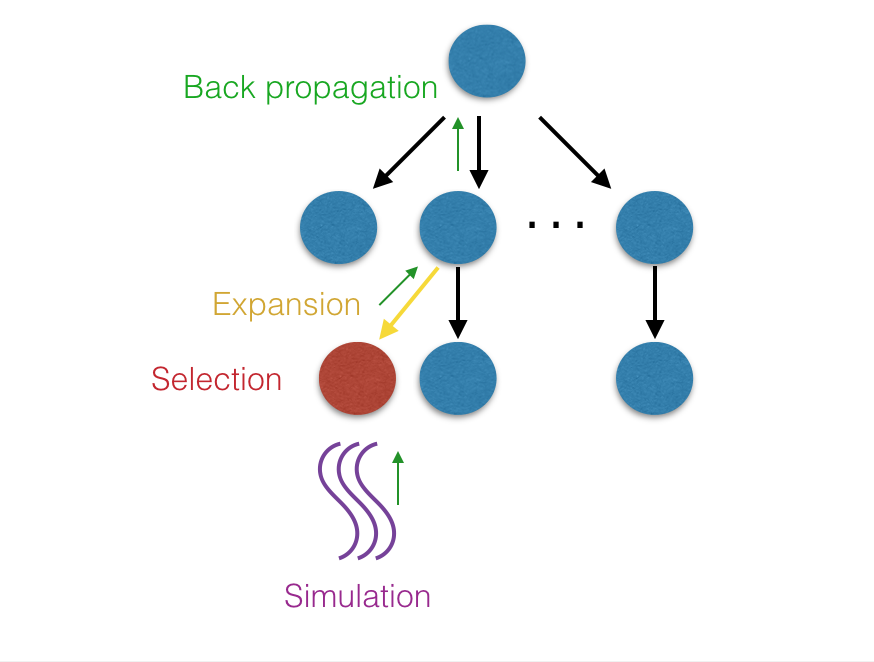
Each node represents a state of the board. To generate a next move, we take the current board state as the root node. With the 4 operations described above, we grow the tree and selects the most promising children of root as next move.
As we know, tree traversal is very hard to parallelize, as there are many dependencies when you go down the tree. However, for Monte Carlo Search Tree, most of the time is spent on Simulation phase on leaf nodes, and these simulation are totally independent from each other. Therefore, there's a potential that we can make simulation phase parallel, so that in a fixed time we can do more simulations for each state of board. Each thread can have a local copy of a board, and they can play randomly on their own board, and then report the result.
However, even though this is naturally parallizable, it's not good for SIMD. Because different threads play the game totally randomly, they will have very different state of board, leading to lots of divergence. We found this problem when we try to run our program on a warp of threads on GPU.
Approach
To implement, for CPU parallel version we use OpenMP, and for GPU parallel we use Cuda. Target machine is Latedays.
At the very begining, we start our project based on Fuego, an open source Go project, to make use of the Go logic they implemented. We tried to understand the code base, interfaces it provides, and tries to parallelize. However, we gradually realize that Fuego is not very friendly to our modification:
1. Fuego provides a very complete and complicated Go logic, and the data structure they use to represent a board state is too large. If we parallelize and do tons of simulation at the same time, it will consume too much memory. We tried solving this problem by using a sequence of play to represent a state of board, instead of their own board data structure, and saves a lot of memory.
2. We wanted to integrate cuda and GPU to Fuego, however, we have to rewrite most of Fuego's code to device code so that it can be run in cuda device. This will be too much work. To avoid the trouble, we implemented a basic version of Go as cuda device code so that we can do Go simulation on GPU.
Implement on CPU:
Leaf-parallel MCTS - On CPU, we used OpenMP to parallelize the Simulation phase of Monte Carlo Tree Search. As mentioned above, this phase starts on the leaf nodes of the tree, and plays randomly on board independently. In OpenMP, we generate a board in each threads private memory so that each thread can play on their own board to avoid conflicts. If sufficient time is given, the tree can become very large because of Go's large expoential search space. At first, we used Fuego's implementation of Board in each node, however, when tree becomes large, program consumes huge memory. Then we changed our tree implementation to that, each node doesn't store a board, instead, it stores the sequence how it reaches this current state.
Implement on GPU:
Implementation on GPU is more complicated. For CPU version, we utilized Go logic implemented by Fuego. However, it's hard to transplant Fuego's code to Cuda device code. After evaluating the workload, we decided to implement our own Go logic in device code. Our own Go logic is a simplified version of Go and is much more lightweight, which is good for parallelizing simulation phase. Smaller data structure repsenting the board is also beneficial when we want to place board data in shared memory to increase the speed for simulating. Some read-only parameters of mcts is stored in constant memory.
The first version of the code is nearly identical to CPU version, just changing the Go play functions to device code. The performance is extremely slow compare, 10 steps in CUDA will take ~20,000ms [9x9 board, same setting for following time measurement], CPU can finish a whole game in ~30 ms. We find out that it is very expensive to malloc and free on device. So, instead of dynamic allocate memory during BFS, we allocate all need resources in advance, and repeat use them. In this way, CUDA can finish whole game in ~2,000 – 3,000 ms. This is a factor of 10 improvements. But CUDA version is still 100X slower than CPU version. Finally, we found that every pointer in CUDA will be stored in global memory, one of our data structure “point” is stored as double pointer, which means we need 3 accesses to global memory to get the actual data. To handle this issue, we change all unnecessary pointers to object and this version can finish whole game under ~1,000 ms in average.
Another improvement is use time constraint for kernel function. Since in MCTS, simulation is done completely random, so the runtime for each thread is unpredictable. The runtime kernel function is always bounded by the longest game, which around ~3,000 - ~4,000 ms, while average game time is under 1,000ms. In order to fully utilize idle thread, we put a time constraint for each kernel thread (1,000 ms for our setting), each thread will keep running until no time left. For game longer than time constraint, it will cutoff and the simulation is counted by a fraction of number of steps already moved. This optimization will improve the total simulations by factor of 1.8X. (for 60s running on 9X9 board with 2048 threads, time constraint version can run 58762 simulations while naïve version can run 32768 simulations.)Leaf-parallel
Leaf-parallel MCTS - We move the simulation phase to GPU so that we can make use of more GPU threads. GPU threads is slower than CPU threads (~100 times slower) due to lower clock frequency. But we can still manage to achieve higher number of simulations by using more threads. After some testing, we found that for threads from same warp will be executed almost sequentially. The reason is a warp of threads is running in SIMD and uses same set of ALU units. These threads are making random plays, leading to very different state of board. This will result in lots of divergence and degenerate to sequential execution. Therefore, we can only increase thread number by increasing the number of blocks and use only one thread on each block. Note that we need to record the number of winning games and total simulations, we use two arraris of size Thread_num and each thread i only writes to array[i] to avoid the use of atomic operation. Then we use exclusive scan to sum up the numbers in the array.
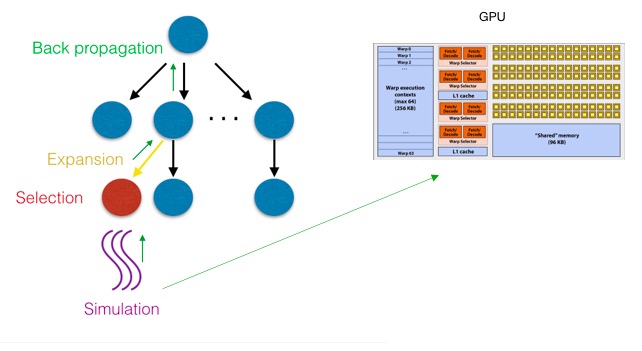
Block-parallel
Block-level MCTS - In leaf-parllel implementation, we parallelize the simulations on a single leaf node. In block-level MCTS, we do simulations on multiple leaf nodes in parallel. Each block is responsible for the simulations of a leaf node. The reason to do block-level MCTS is to reduce the probability to converage to a local optimum.
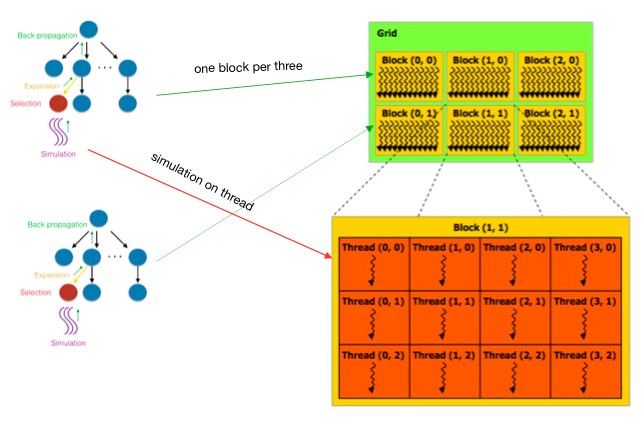
Hybrid GPU & CPU
Finally, when the GPU is doing simulation works, CPU is idle to wait for GPU. This is a good opportunity to utilize CPU. Based on this observation, we hybrid GPU and CPU to further improve our performance. As shown in result, the hybrid method fully utilized CPU power when GPU is doing work.
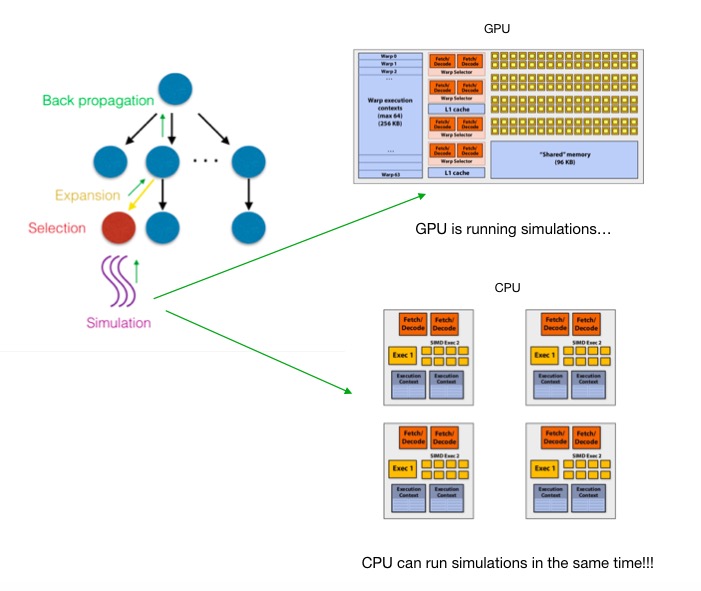
Result
We run several experiments to show the performance between serialization, CPU parallelism and GPU parallelism. The results show that our GPU parallel MCTS is 1.7X faster than the CPU version on the best setting for both methods. And our Hybrid GPU & CPU method is 2.1X faster then CPU on the best setting.
We found two facts in the experiments: 1. single thread CPU is 40X - 200X faster than single thread GPU based on the board size and implementation. The reason is that CPU core is more sophisticated than GPU core, higher clock frequency, instruction pre-fetching, branch prediction, etc. 2. The simulation for GO is compute-bound, and each step in simulation is random, so the divergence is very high. This means MCTS simulation actually is not suitable for GPU, the high divergence and compute-bound characteristics means multithreading on one core is not useful. The experiments showed multithreading on GPU will turn to serialization. So the following experiments using the 1 thread per block setting.
CPU leaf-parallel
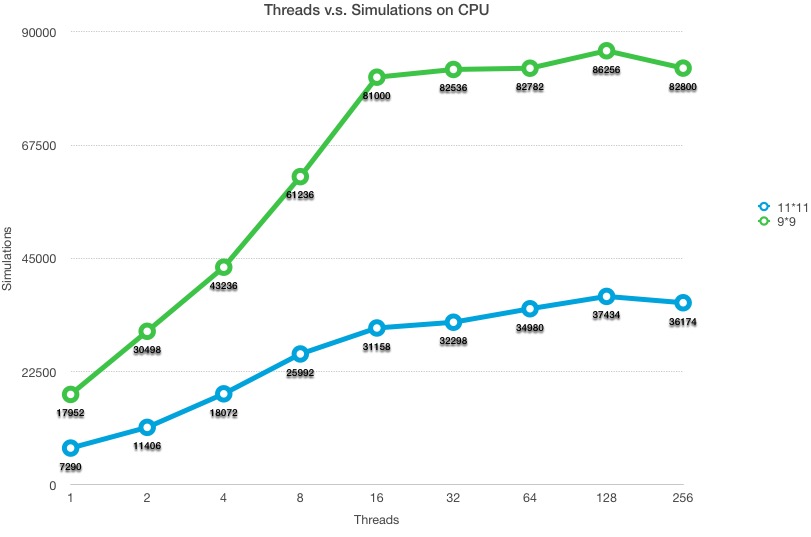
The following figure describes the speedup we get on 9x9 Go board and 11x11 Go board, and the machine we used is two 6-core Xeon e5-2620 v3 processors. For 9x9 board, we got almost leaner speed up for using 1 to 16 cores. This is reasonable because the our algorithm is very computation heavy and most of the time is spent on simulation. Increasing number of cores should increase number of simulations almost linearly. The slow speedup increases from 16 to 128 should be due to multi-threading and latency hiding. Each board data structure (9x9) is ~1KB so boards from all threads should be able to hold in cache. The effect of latency hiding is not obvious.
Program with 11x11 board is significantly slower because one simulation typically takes longer to finish.
GPU leaf-parallel
This experiment is conducted on latedays cluster NVIDIA TitanX GPU, which has 3072 cores in total. The total running time for each execution is 120 seconds. The comparison is between different threads and how many simulations the MCTS can run given the time constraint. We run this experiment on two different board sizes, 9X9 and 11X11. Time time contraint for 9X9 is 1,000 ms and 11X11 is 4,000 ms.
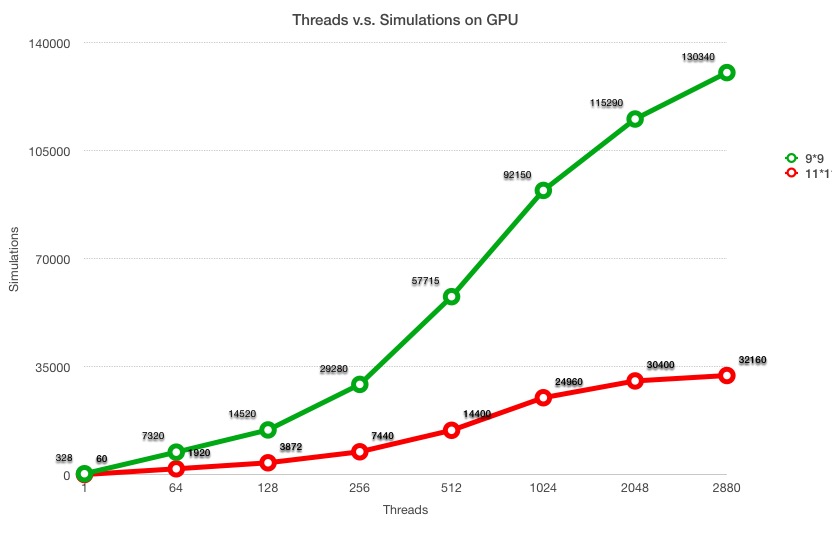
As we can see from the graph, the simulations increasing linearly as the threads increasing. When threads beyond 1024, we found the that the synchronization overhead between threads increasing fast. In the experiment, each core is given 1000 ms time constraint, however, the total kernel function execution time is over 2000 ms and increasing as the threads number going up. As mentioned above, the experiment use 1 thread per block, so the actual synchronization is between cores. Another limitation is the number of cores on the GPU. Since the simulation is compute-bound operation, so the number of cores decides the maximum threads can be executed in parallel.
Hybrid GPU & CPU
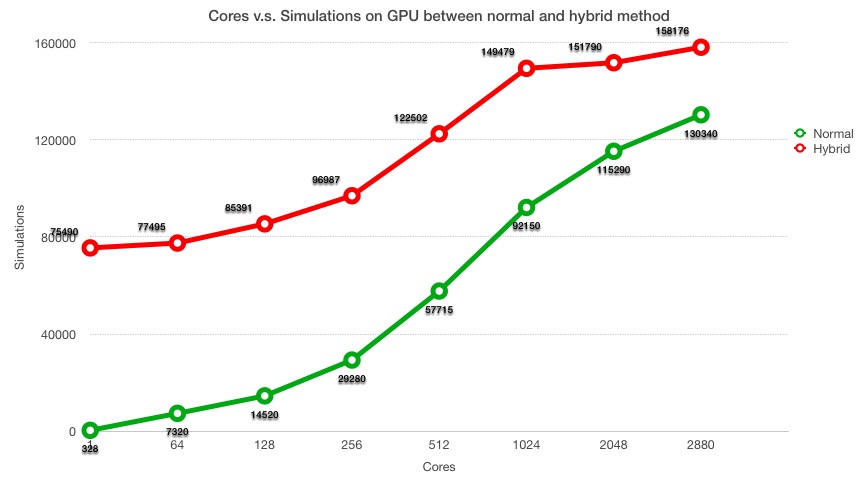
This experiment is running on the work node that has NVIDIA K40 GPU (2880 cores) and Xeon Phi 5 CPU (60 cores). The total running time for each execution is 120 seconds. For CPU simulation, we use 59 threads (fully utilize other 59 cores). The time constraint is 1,000ms for GPU kernel function and CPU threads. The board size is 9X9. NOTE: The NORMAL data run on NVIDIA TitanX GPU, which is powerful than K40.
We can see a clearly gap between two approaches, which is the benefit from utilize the idle CPU. Notice that when the number of threads reaching to 1024 threads, the gap becomes narrow. This is because the overhead of synchronization between different CUDA cores increasing, the actual CPU threads benefits decreasing. When threads number is 2048, the total running time for GPU kernel function is around 2,000 ms, while the time constraint for CPU threads in 1,000 ms, which means half of the time will waste for CPU. In general, hybrid method has better performance than GPU approach.
Comparison between different parallel approaches
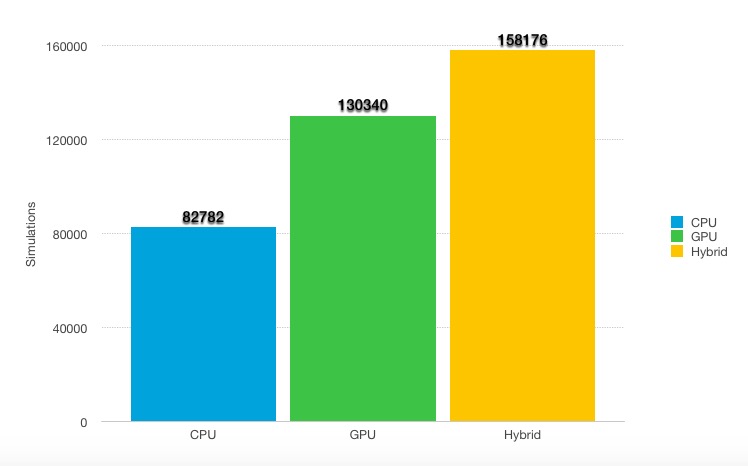
The data is from previous experiment. Our GPU approach achieves 1.5X speedup than CPU and the hybrid method achieves 1.9X speedup. The main limitation of GPU approach for MCTS is mentioned before, MCTS simulation is compute-bound and has high divergence, which means only 1/32 of the compute resources are utilized. In addition, for single core, GPU has lower performance than CPU core, nearly around 40X – 200X depends on implementation and board size.
Competition between different parallel approaches
The machine setup is the same as prevous experiment. Since we only have limited time, so totally played 10 games for each comparasion. For each game, 120 moves are made, each move has 20 seconds "thinking" time. The board size is 9X9.
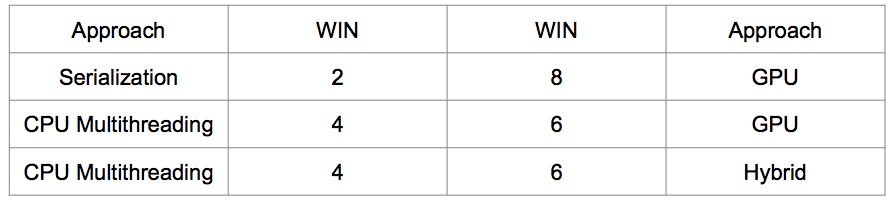
We can see that GPU approach is clearly better than serialization approach. Since the board size is pretty small and games player is small, the game between CPU, GPU and Hybrid not shown big difference.
Reference
[1] Rocki, Kamil, and Reiji Suda. "Parallel Monte Carlo Tree Search on GPU." SCAI. 2011.
[2] Jeff Bradberry, Introduction to Monte Carlo Tree Search, https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/
[3] Guillaume M.J.-B Chaslot, "Parallel Monte Carlo Tree Search", Computers and Games: 6th International Conference
Work distribution:
Equal work was performed by both project members.